2) 데이터베이스 기초 활용하기
- 데이터베이스의 종류
-> 오라클의 Oracle과 MySQL, 티맥스의 Tibero, MSN사의 SQL Server, IBM의 DBI등
-> 오픈소스로는 PostgreSQL, MariaDB 등
- RDBMS : 테이블 구조관계 기본키, SQL 질의어
- OODBMS : 엔티티간 포인팅 방식 객체 식별(OID), OQL(Object Query Language)
- ORDBMS : RDBMS + OODBMS, SQL 확장질의어 사용(SQL3)
- NoSQL(Not Only SQL) -> 페타바이트 수준의 대량의 데이터처리
NoSQL은 수평적 확장이 가능, 다수 서버들에 데이터 복제 및 분산 저장이 가능
- Schema-less : 고정된 데이터 스키마 없이 키(key)값을 이용해 다양한 형태의 저장과 접근가능
- 탄력성(Elasticity) : 일부 장애에도 불구하고 다운타임이 없음, 시스템 규모와 성능 확장 용이 -> 입출력의 부하연산에도 용이
- 효율적 질의 기능
- 캐싱(Caching) : 대규모의 질의에도 고성능 응답속도를 제공할 수 있는 메모리 기반의 캐싱 기술 적용
- NoSQL의 데이터 저장구조
- Key/Value Store : Unique한 Key하나의 Value를 가짐, Value := get(key) API로 접근
- Ordered Key/Value Store : Key/Value Store에서 내부적으로 Key순서로 Sorting됨
- Document Key/Value Store : 저장되는 데이터 타입이 Document 타입 -> XML, JSON, YAML
- 모델별 주요 NoSQL 제품
- Key/Value Store : Redis, Riak, Voldemort, Dynamo DB
- Column Family Data Store : HBase, Cassandra, Hypertable, SimpleDB
- Document Store : MongoDB, Couchbase
- Graph Database : Neo4j, AllegroGraph
- 데이터 독립성
데이터의 저장 구조와 접근 기법으로부터 응용을 분리시키는 개념
-> 데이터베이스에 대한 사용자 View와 DB의 구현 View를 분리하여 변경에 따른 영향을 줄임
-> 계층별 View에 영향을 주지 않고 변경이 가능
- 논리적 독립성 : 논리적 구조를 변형시키더라도 기존 응용 프로그램에 영향을 주지 않는 것 -> 하나의 논리적 구조를 가지고 많은 응용프로그램이 제각각 요구하는 다양한 형태의 논리적 구조로 사상
- 물리적 독립성 : 응용 프로그램과 논리적 구조에 영향을 주지 않고 데이터베이스의 물리적 구조를 변경
- 3단계 데이터 스키마 구조
- 내부 단계 : 물리적인 기억장소와 가장 가까운 단계, 데이터가 물리적으로 저장되는 방법과 관련
- 개념 단계 : 내부와 외부 단계의 사이에 위치하는 간접 단계, 데이터베이스 전체에 대한 추상적 개념
- 외부 단계 : 사용자와 가장 가까운 단계로 사용자 개개인이 보는 자료에 대한 관점과 관련
- EA(Entity Relationship) 모델
70년대 피터 첸에 의해 개발


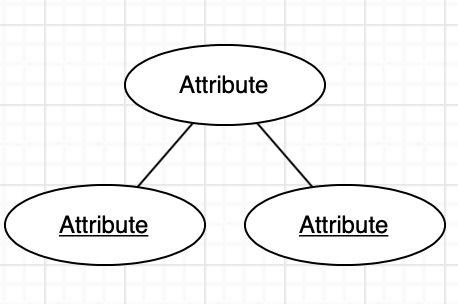
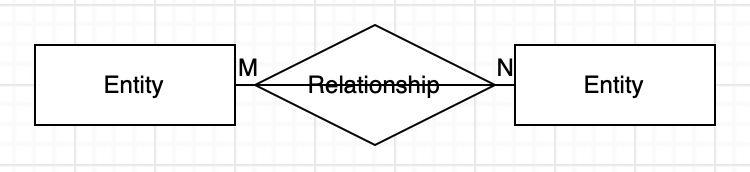

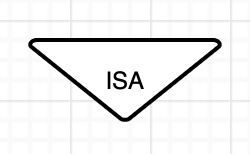
- 관계형 데이터 모델
- 용어
- 도메인 : 하나의 속성이 가질 수 있는 값들의 범위
- 릴레이션 스키마 : 릴레이션의 이름과 속성이름의 집합(릴레이션의 구조)
- 릴레이션 인스턴스 : 릴레이션에서 어느 시점까지 입력된 튜플들의 집합
- 차수 : 릴레이션을 구성하는 속성(항목)의 수
- 카디널리티 : 릴레이션에 입력된 튜플(행)의 수
- ER 모델에서 관계형 데이터 모델로의 변환
- 매핑 룰 : 개념적 데이터 모델인 ER모델을 논리적 데이터 모델인 릴레이션 스키마로 변환하는 것
- 1대1 관계 : 릴레이션 A의 기본키를 릴레이션 B의 기본키 혹은 외래키로 추가하여 표현 -> 잘 안쓰임
- 1대N 관계 : 릴레이션 A의 기본키를 릴레이션 B의 외래키로 추가하여 표현
- N대M 관계 : 릴레이션 A와 B의 양쪽 모두의 기본키를 모두 포함한 별도의 릴레이션으로 표현
- 키의 개념 및 종류
- 키 : 튜플들을 서로 구분할 수 있는 기준이 되는 속성들
-> 유일성 : 하나의 키 값으로 하나의 튜플만을 유일하게 식별 -> 기본키, 후보키, 슈퍼키
-> 최소성 : 속성의 집합인 키가 릴레이션의 모든 튜플을 유일하게 식별하기 위해 꼭 필요한 속성들로 구성된 것 -> 기본키, 후보키
- 후보키 : 릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별할 수 있는 하나 또는 몇개의 속성의 집합
- 기본키 : 릴레이션의 유일한 식별자, 같은 값을 갖지 못함, 후보키 중 선정, Not Null, Unique, 외래키 참조 가능
- 대체키 : 기본키로 선택되지 못한 후보키
- 슈퍼키 : 유일성만 있고 최소성이 없는 속성의 집합
- 외래키 : 한 테이블의 키 중 다른 테이블의 튜플을 식별할 수 있는 키
- 무결성
데이터베이스에 저장된 데이터 값과 그것이 표현하는 현실 세계에서의 실제 값이 일치하는 정확성
- 개체 무결성 : 기본키는 반드시 값을 가짐, 유일성을 보장하는 최소한의 집합 -> Primary Key, Not Null
- 참조 무결성 : 외래키 속성은 반드시 참조 되어야 함 -> 외래키 값은 그 외래키가 기본키로 사용된 릴레이션과 참조 무결성 제약을 가짐 -> Foreign Key
- 속성 무결성 : 컬럼은 지정된 데이터 형식을 반드시 만족하는 값만 포함
- 키 무결성 : 한 릴레이션에 같은 키 값을 가진 튜플들은 허용 안됨 -> Primary, Unique
- 사용자 정의 무결성 : 모든 데이터는 업무 규칙을 준수해야 함
- 도메인 무결성 : 특정 속성 값이 미리 정의된 도메인 범위에 속해야 함
정보처리기사 실기 - 10. 응용 SW 기초 기술 활용(5) /데이터베이스 기초 활용하기 -2
- 관계 대수(Relation Algebra) 관계형 데이터베이스에서 원하는 정보와 그 정보를 어떻게 유도하는가를 기술하는 절차적 언어 - 순수관계 연산자 select : 시그마(σ) : σ(조건)(R) project : 파이(π) : π(속.
aapslie94.tistory.com
'전공 > 정보처리기사 실기' 카테고리의 다른 글
| 정보처리기사 실기 - 10. 응용 SW 기초 기술 활용(6) /네트워크 기초 활용하기 -1 (0) | 2021.05.17 |
|---|---|
| 정보처리기사 실기 - 10. 응용 SW 기초 기술 활용(5) /데이터베이스 기초 활용하기 -2 (0) | 2021.05.16 |
| 정보처리기사 실기 - 10 . 응용 SW 기초 기술 활용(3) /운영체제 기초 활용하기 -3 (0) | 2021.05.15 |
| 정보처리기사 실기 - 10. 응용 SW 기초 기술 활용(2) /운영체제 기초 활용하기 -2 (0) | 2021.05.15 |
| 정보처리기사 실기 - 10. 응용 SW 기초 기술 활용(1) /운영체제 기초 활용하기 -1 (0) | 2021.05.15 |